ネットワークファブリック(Network Fabric)とは?
ネットワークファブリックとは?

ネットワークファブリックの仕組みは?
仮想化は大きな価値を提供し、アンダーレイを複数のオーバーレイネットワークに分割できるようにします。これらの各仮想ネットワークは、異なるニーズを満たすために独自のポリシーによって最適化できます。
さらに、ネットワークファブリックはポリシーベースの制御と自動化のための広範なメカニズムを使用し、ビジネス要件に基づいて迅速に変更に適応することができます。仮想化、ポリシー制御、自動化の組み合わせにより、データセンターの構築において非常に効率的、柔軟、かつ応答性の高いネットワークインフラを実現します。
ネットワークファブリックが必要な理由
ネットワークファブリックは、企業が多様なユーザーベースの要求を満たすことを可能にします。これは、基盤となる物理的ネットワークに依存せず、ポリシーの均一な適用を可能にするためです。これにより、有線・無線を問わず、金融システムからCRMや販売ソフトウェアまで、さまざまなアプリケーションをサポートすることが重要です。
キャンパス、支社、WAN、データセンターネットワーク(ハイブリッド構成を含む)全体にわたってネットワークファブリックを統合することにより、企業はシームレスで企業全体のファブリックを作成できます。この統合により、企業全体のネットワークインフラのパフォーマンス、セキュリティ、管理性が向上します。
ネットワークファブリックのメリット
ネットワークファブリックは、以下のメリットを提供します。
このような魅力的なメリットから、ネットワーク・ファブリックは多くの企業ネットワークで広く採用されています。
まとめ
FSは、ネットワーク構築のためのネットワーク機器の提供に加え、ハードウェアを最適化し、ビジネス目標を達成するためのネットワークポリシーやセキュリティ対策を実施するインターネットデータセンターソリューション、エンタープライズLANソリューション、エンタープライズWLANソリューションも提供しています。
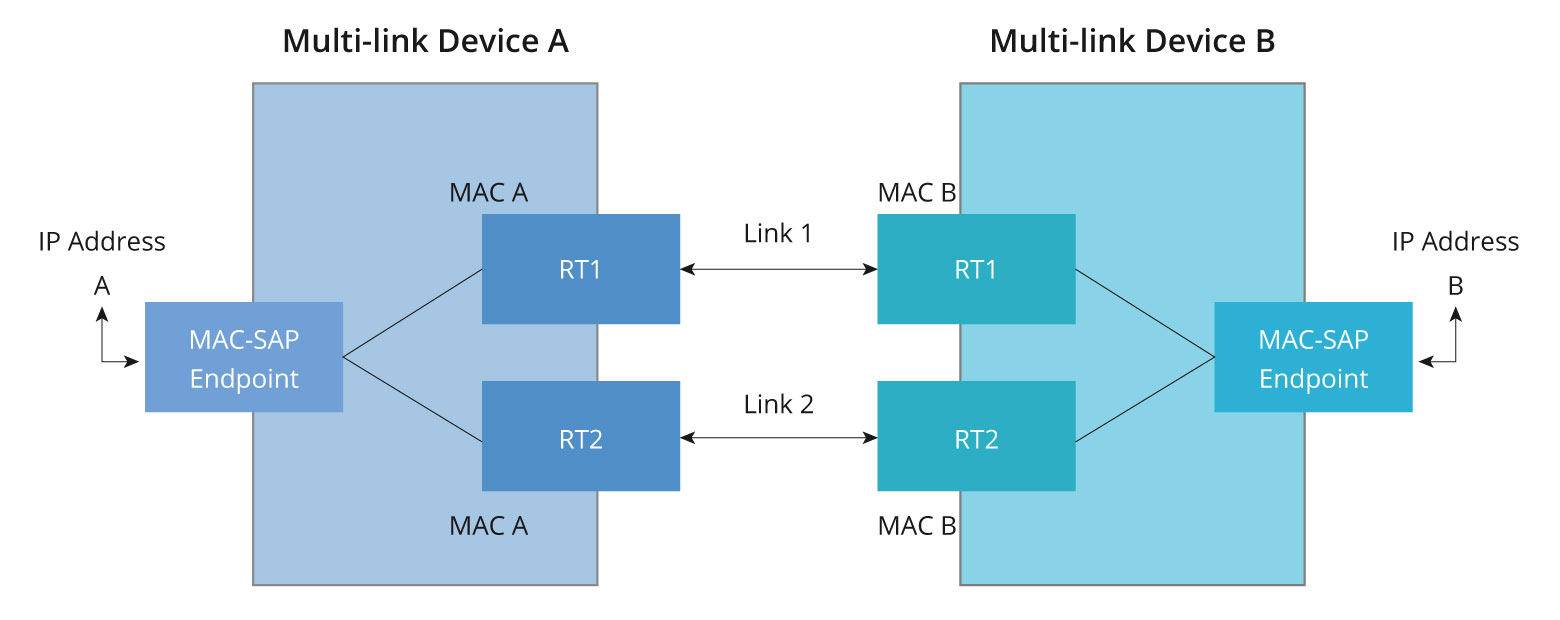
マルチリンクオペレーション(MLO):Wi-Fi のゲームチェンジャー
MLOとは?

Wi-Fi 7のMLOは、異なる周波数帯にわたる複数のチャネルを同時に集約することにより、この問題に対処します。これにより、干渉や混雑があってもネットワークトラフィックがスムーズに流れ、高速化が実現します。また、効率的なメッシュネットワークを実現し、先進的な干渉緩和技術を取り入れて、混雑したネットワーク環境でもワイヤレスデバイスが迅速かつ信頼性高く接続されるようになります。MLOにより、Wi-Fi 7は、スマートフォンのようなデバイスとWi-Fiアクセスポイント(ルーターなど)との間で、2.4 GHz、5 GHz、6 GHz帯を同時に利用して複数の接続を確立できます。これにより、スループットが向上し、レイテンシが低下し、信頼性が増します。これにより、VR/AR、オンラインゲーム、リモートワーク、クラウドコンピューティングなどのアプリケーションに最適です。
Wi-Fi 7 MLOのメリット
データレートを向上させる効果的な方法は、複数のチャネルを横断して異なるデータストリームを同時に送受信することです。このアプローチは、ビデオ会議やOTTストリーミングのようなデータ集約型のリアルタイムアプリケーションに対応しています。
リンク選択によるレイテンシの改善
驚くべきことに、選ばれたチャネルは必ずしも通常の予想に一致するわけではありません。例えば、2.4 GHzはしばしば遅いと考えられがちですが、他の帯域が混雑している場合、最適な選択肢となることがあります。最優先されるのは、初回のデータ送信で成功する可能性を最大化するチャネルを選択することで、これにより低レイテンシと高データレートを実現し、ユーザーにとって本当に重要な結果をもたらします。
このアプローチは、以前のモードの強みを活かしつつ、いくつかの追加のメリットを提供:
Wi-Fi 7の機能におけるMLOの位置づけ
FS Wi-Fi 7 APで将来に備えましょう
Wi-Fi 7が接続性を強化する革新的な機能であるMLOを導入する中で、最新技術を先取りすることが重要です。FSのWi-Fi 7アクセスポイント(AP)は、MLOの全潜力を活用するように設計されており、比類のない速度、信頼性、効率性を提供します。高密度環境、VR/ARのような要求の高いアプリケーション、リモートワークシナリオでのシームレスな接続を支援するために、FSのWi-Fi 7 APは、今日および未来のワイヤレスネットワークに必要な強力なパフォーマンスを提供します。
まとめ
Wi-Fi 7の進展を今取り入れることで、あなたのネットワークは明日の課題に対応できるようになり、さまざまなアプリケーションで最高のユーザー体験を提供します。今後、MLOがワイヤレス技術に与える影響はますます大きくなり、現代のネットワークインフラにおいて不可欠な要素となるでしょう。
EVPNマルチホーミングとMLAG:主な違い
MLAGとは?

EVPNマルチホーミングとは?
EVPNマルチホーミングは、データセンターや企業ネットワークでのAll-Activeサーバ冗長性を実現する標準ベースのソリューションです。

MLAGのアプリケーション
MLAGは、VXLANやSDNオーバーレイを使用しない、予算が限られた小規模なネットワークに最適です。
データセンターでの従来のデュアルホーミング
MLAGは、アクティブ/アクティブ構成のサーバとスイッチ接続のシナリオに理想的で、デバイス間リンクアグリゲーションによるリンクレベルの冗長性を提供します。この設定では、物理サーバが2台のスイッチに接続し、バンドルされたデュアルネットワークアダプタを通じてアクティブ・アクティブ接続を確立できます。ストレージデバイスもアクティブ/アクティブ接続を確立し、単一障害点を排除します。この構成はシンプルで、既存のLayer 2ネットワークに大きな変更を加えることなく実現できます。
中小規模ネットワーク向けの高可用性
EVPNマルチホーミングのアプリケーション
VXLANオーバーレイネットワークのマルチホーミング
大規模クラウドネットワークとマルチテナント環境
マルチベンダーネットワークでの相互運用性
EVPNマルチホーミング vs MLAG
|
機能
|
MLAG
|
|
|
冗長性
|
説明:マルチポイント冗長性、複数のデバイスをサポートし、障害の中心点なし。
|
|
|
評価: ⭐️⭐️⭐️⭐️⭐️
|
評価:⭐️⭐️⭐️⭐️
|
|
|
信頼性
|
説明:分散制御により単一障害点がなくなり、最適な信頼性が実現。
|
説明:リンクアグリゲーションでネットワークの信頼性を向上。
|
|
評価:⭐️⭐️⭐️⭐️⭐️
|
評価:⭐️⭐️⭐️
|
|
|
拡張性
|
説明:理論上無制限の拡張性。
|
説明:2台のデバイスをサポート
|
|
評価:⭐️⭐️⭐️⭐️⭐️
|
評価:⭐️⭐️
|
|
|
管理性
|
説明:標準プロトコルに基づき、管理は比較的簡素化されていますが、EVPNの知識が必要。
|
|
|
評価:⭐️⭐️⭐️
|
評価:⭐️⭐️⭐️
|
|
|
互換性
|
説明:BGP-EVPN標準に準拠、最強の互換性。
|
説明:ベンダー固有の実装。
|
|
評価:⭐️⭐️⭐️⭐️⭐️
|
評価:⭐️️
|
|
|
応用シナリオ
|
VXLANオーバーレイネットワークマルチホーミングアクセス
大規模クラウドネットワークとマルチテナント環境
異種ベンダーデバイスハイブリッドネットワーキング
大規模データセンター
|
従来のデータセンターデュアルホーミングアクセス
中規模企業またはデータセンター
|
FSがご提供するサポート
ネットワークが成長し、クラウドコンピューティング環境が拡大する中で、EVPNマルチホームはそのスケーラビリティ、分散型アーキテクチャ、および標準化された特性により、高可用性ネットワークの主なソリューションとなるでしょう。MLAGは、中規模ネットワークのニーズに対して引き続き価値があります。
FSは、10G、25G、100Gのデータセンター向けスイッチを提供しており、MLAGとEVPNマルチホームの両方をサポートしています。これにより、さまざまなシナリオでお客様の要求に対応することができます。PicOS®スイッチは、統一されたPicOS®とAmpCon-DC SDNコントローラを活用し、運用、メンテナンス、構成を自動化することで、データセンターの効率とシステムの安定性を大幅に向上させます。
CLIとWebインターフェースによるスイッチVLAN構成
CLIおよびWebインターフェースとは?
CLI(Command Line Interface)とは、テキストベースのインターフェースであり、プロンプトにコマンドを入力することでネットワーク機器を構成・管理する手段です。
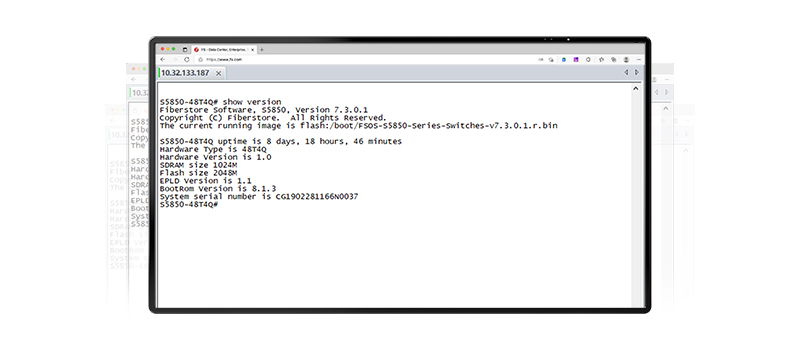
設定コマンドを入力すると、ネットワークソフトウェアがそのコマンドを認識し、ネットワーク機器の状態を監視できるようになります。以下の図は、FS S5850-48T4QイーサネットスイッチのCLI画面を示しています。
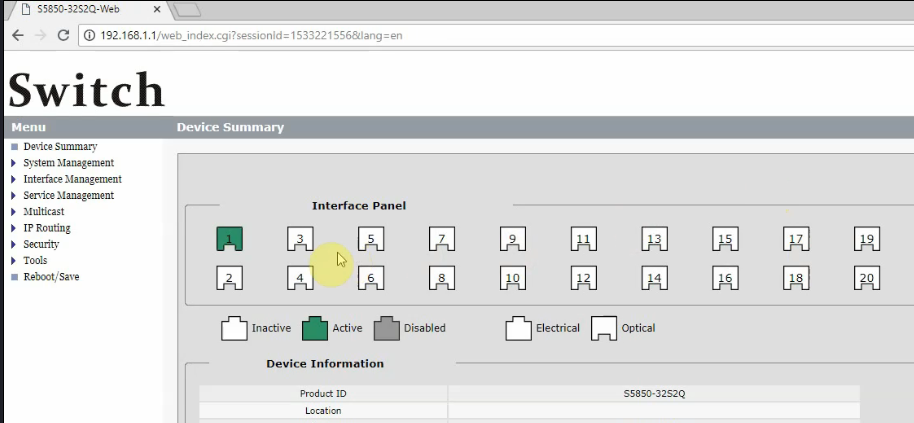
Webインターフェース(Web User Interface)またはWeb UIは、グラフィカルユーザーインターフェース(GUI)とも呼ばれます。Webインターフェースは視覚的な操作が可能な管理画面を提供し、Webブラウザ上でデータスイッチの設定を行うことができます。以下の図は、WebブラウザでのWeb UIの表示例です。Webインターフェースを使用すると、接続されているデバイスの基本情報を確認し、ネットワーク設定の変更を行うことが可能です。
データスイッチのCLIおよびWebインターフェースへのアクセス方法
CLIへのアクセス手順
最も簡単なCLIへのアクセス方法は、コンピューターとデータスイッチを直接シリアル接続することです。上記の動画のとおり、コンピューターをスイッチのコンソールポートにコンソールケーブルで接続し、以下の手順を実行します。
1. SecureCRTソフトウェアをコンピューターにインストールして実行
2. コンピューターのCOMポートを確認し、スイッチとの接続が確立されていることを確認
3. COM3ポートのボーレートおよび基本パラメータを設定し、すぐに接続できるようにする
4. コマンドを入力:#enter
エラーメッセージが表示されなければ、CLIへのアクセスが成功
Webインターフェースへのアクセス手順
WebインターフェースへのアクセスはCLIよりやや複雑ですが、コンピュータとスイッチを接続した後、以下の手順に従って設定を行います。
1. SecureCRTソフトウェアをコンピュータで実行
#configure terminalを実行してグローバル設定モードに入る
2. “http”ファイルを選択し、"http" サービス(Web機能)を有効化
#interface eth-0-1でeth-0-1 ポートに入る
#show interface eth-0-1でスイッチのeth-0-1ポートの状態を確認
#no switch portでeth-0-1ポートをL3モードに設定(ルーティングポート化)
3. eth-0-1ポートにIPアドレスを割り当てる
#no shutdownを実行してeth-0-1ポートを有効化
4. コンピュータのIPアドレスを、eth-0-1ポートと同じネットワークに設定
6. Web UIに、対応するIPアドレスでログイン
CLIおよびWebインターフェースを使用したVLAN設定方法
CLIを使用したVLAN設定
上記の動画のとおり、CLIを使用したVLAN設定は4つのステップで構成されています。以下の表に記載されたVLAN設定コマンドを実行すると、スイッチ上で作成されたすべてのVLANを表示および管理できます。
|
手順
|
コマンド
|
目的
|
|
Step 1
|
#enter
|
CLIインターフェースに入る
|
|
Step 2
|
#configure terminal
|
グローバル設定モードに入る
|
|
Step 3
|
#vlan database
|
VLAN 設定モードに入る
|
|
Step 4
|
#show vlan all
|
このスイッチ上のすべての VLANの詳細を確認
|
Webインターフェースを使用したVLAN設定
WebインターフェースでのVLAN設定は非常にシンプルです。以下の3つのステップを実行すると、Webインターフェースのサービス管理でVLANを追加または削除できます。
Step 1:ブラウザを開き、IPアドレス「192.168.1.1」を入力
Step 2:アカウントのユーザー名とパスワードでログインし、Webインターフェースに入る
Step 3:サービス管理でVLANを追加または削除できる
まとめ
MPLSネットワークにおけるBGPの活用
本記事では、BGPとMPLSの関連性を詳しく解説し、効率的で柔軟なネットワークアーキテクチャの構築をサポートします。
BGP:グローバルネットワークを接続する基幹プロトコル
MPLS:効率的なパケット転送技術
MPLSはIPフォワーディングをラベルスイッチングに置き換え、ラベルを使用してパケットを転送します。このラベルは短く、ローカルでのみ意味を持つ識別子です。
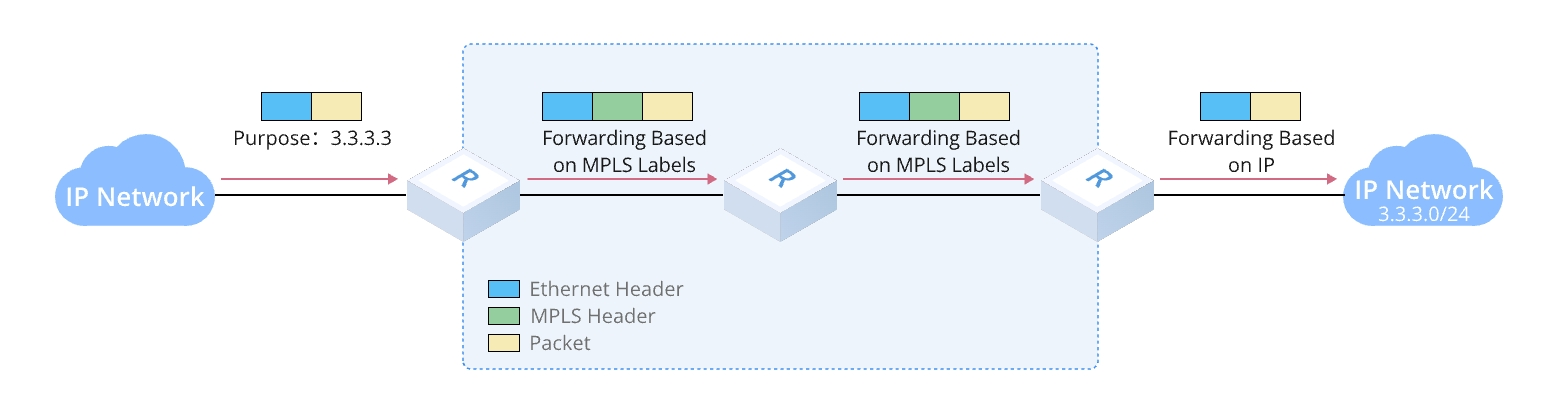
MPLSの基本用語と概念
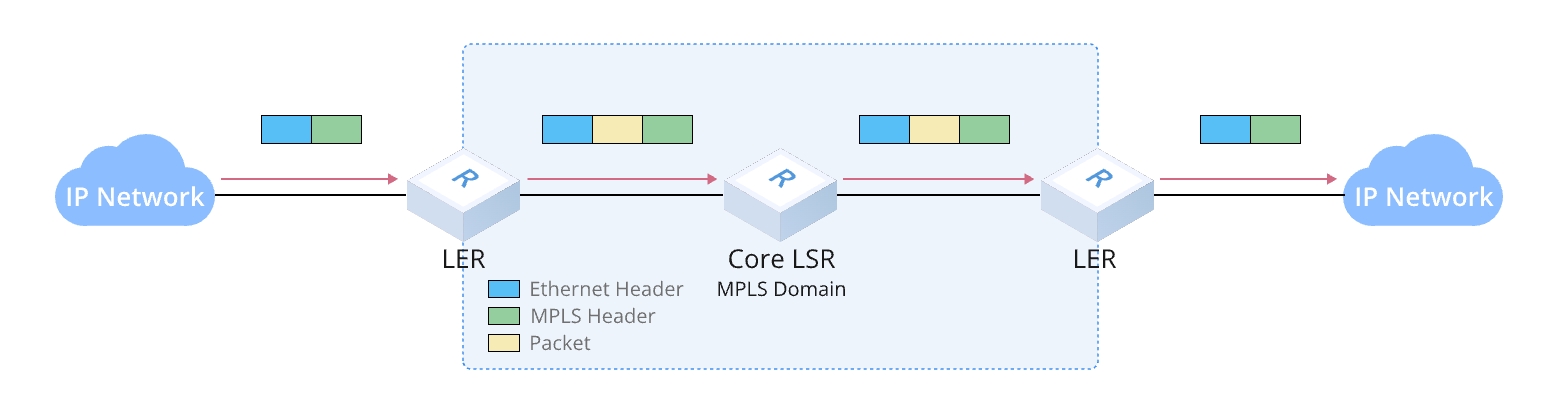
LSRの分類
LSRは設置場所に加え、ラベル処理の方法によっても分類できます。LSRはMPLSドメイン内での位置とデータ処理方法に基づき、以下の3つに分けられます。
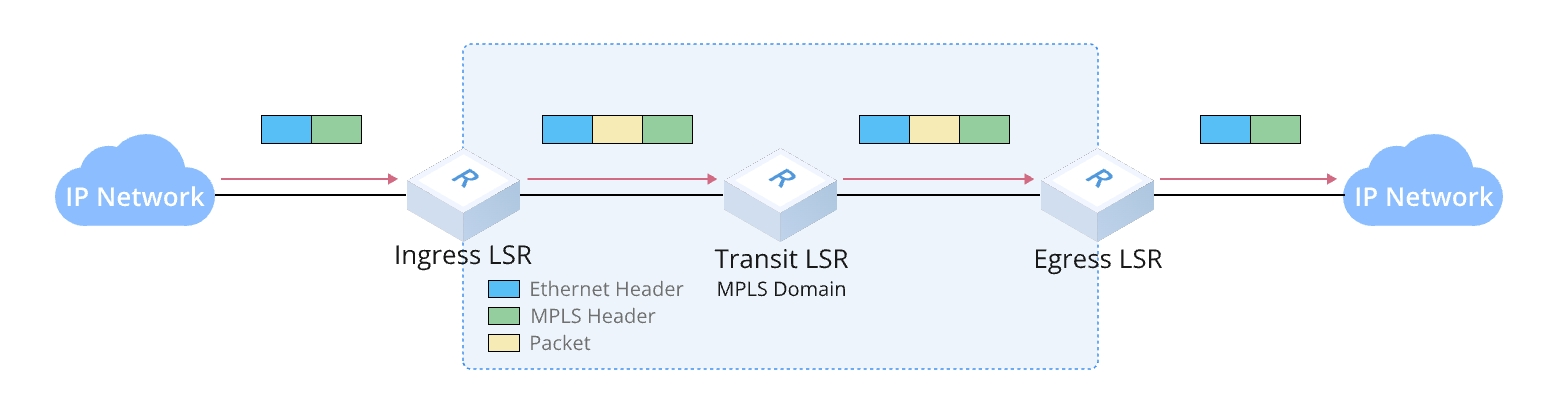
FEC(Forwarding Equivalence Class)
FEC(転送等価クラス)とは、一定の共通特性を持つデータストリームの集合であり、ネットワークノードが転送時に同じ方法で処理するグループを指します。
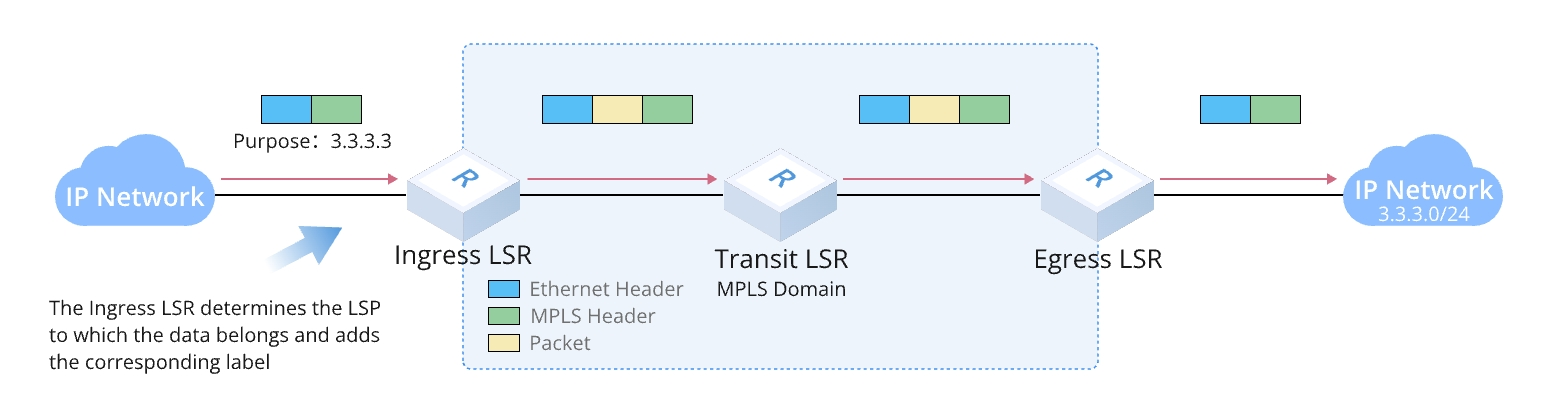
LSP (Label Switched Path)
LSP(ラベルスイッチパス)は、MPLSネットワークを通過するラベル付きパケットの経路であり、FECと関連しています。同じFECに属するパケットは、通常、同じLSPを通じてMPLSドメインを横断します。そのため、同じFECのデータに対して、LSRは常に同じラベルで転送を行います。
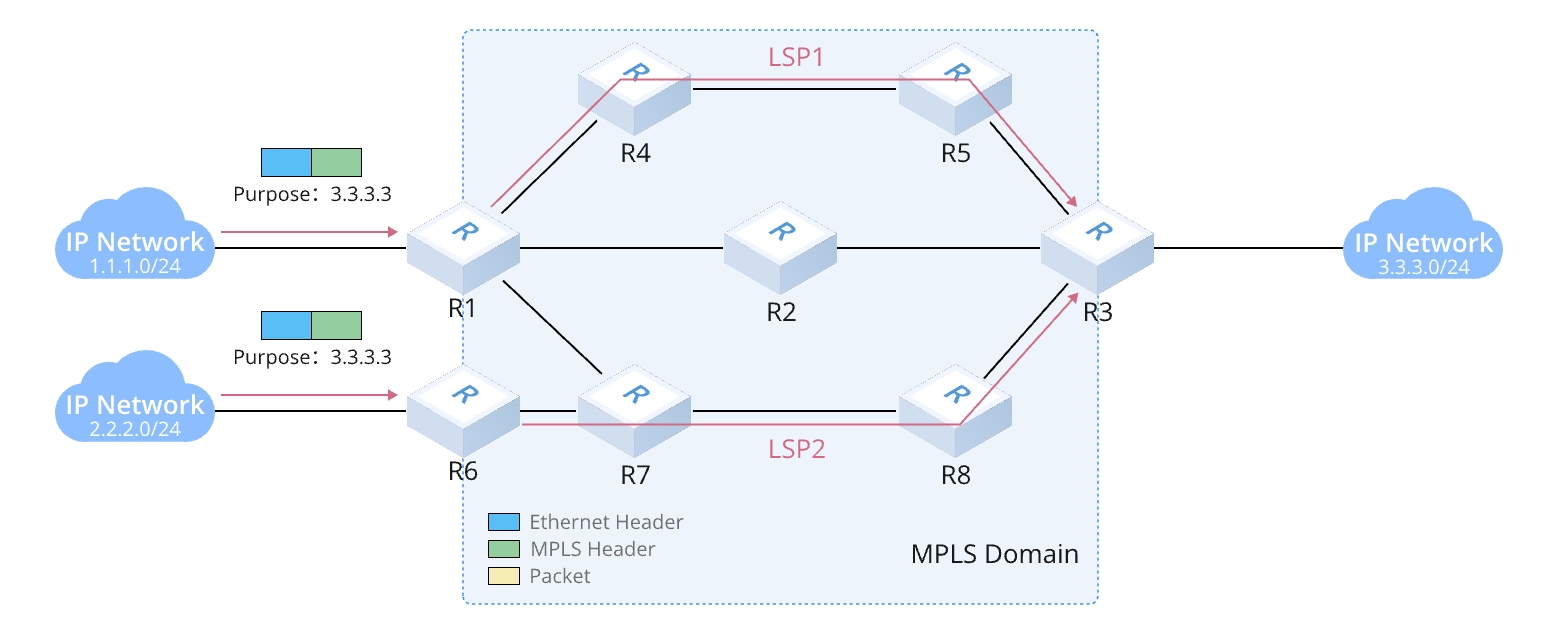
MPLSネットワークにおけるBGPの役割
MPLS VPNにおけるBGPの中核的役割
MPLSトラフィックエンジニアリング(MPLS-TE)におけるBGPの役割
3. 柔軟なルーティング制御:BGPの**Color-Aware Routing(カラーアウェアルーティング)**をMPLS-TEと組み合わせることで、トラフィックの分散制御が可能になり、SD-WANや5G伝送ネットワークに適用できます。
MPLS L3VPNおよびL2VPNサービスにおけるBGPの役割
MPLS VPNは、実装レイヤーに基づいてMPLS L2VPNとMPLS L3VPNに分類されます。
まとめ
BGPとMPLS/VPNの構成を理解することで、ネットワーク管理者はより効率的なネットワークアーキテクチャを設計・実装し、データの安全性とパフォーマンスを確保できます。インターネットサービスプロバイダー、企業のマルチデータセンター、クラウドコンピューティング環境において、BGPとMPLSは効率的で柔軟なネットワーク構築を実現する強力なツールです。
BGP vs. OSPF vs. IGP vs. VRRP:違いは?
BGP、OSPF、IGP、VRRPの概要
BGPプロトコル
BGPの初期バージョンにはBGP-1、BGP-2、BGP-3があり、それぞれのバージョンで機能とパフォーマンスが向上し、インターネットの規模拡大や需要増加に対応してきました。現在最も広く使用されているのはBGP-4であり、BGP-3と比較して多くの新機能と改良が加えられています。これにより、BGP-4はより柔軟で信頼性が高く、今日の複雑なネットワーク環境やビジネスニーズに適したプロトコルとなっています。
BGPの動作原理と機能の詳細については、別途説明を参照してください。
OSPFプロトコル
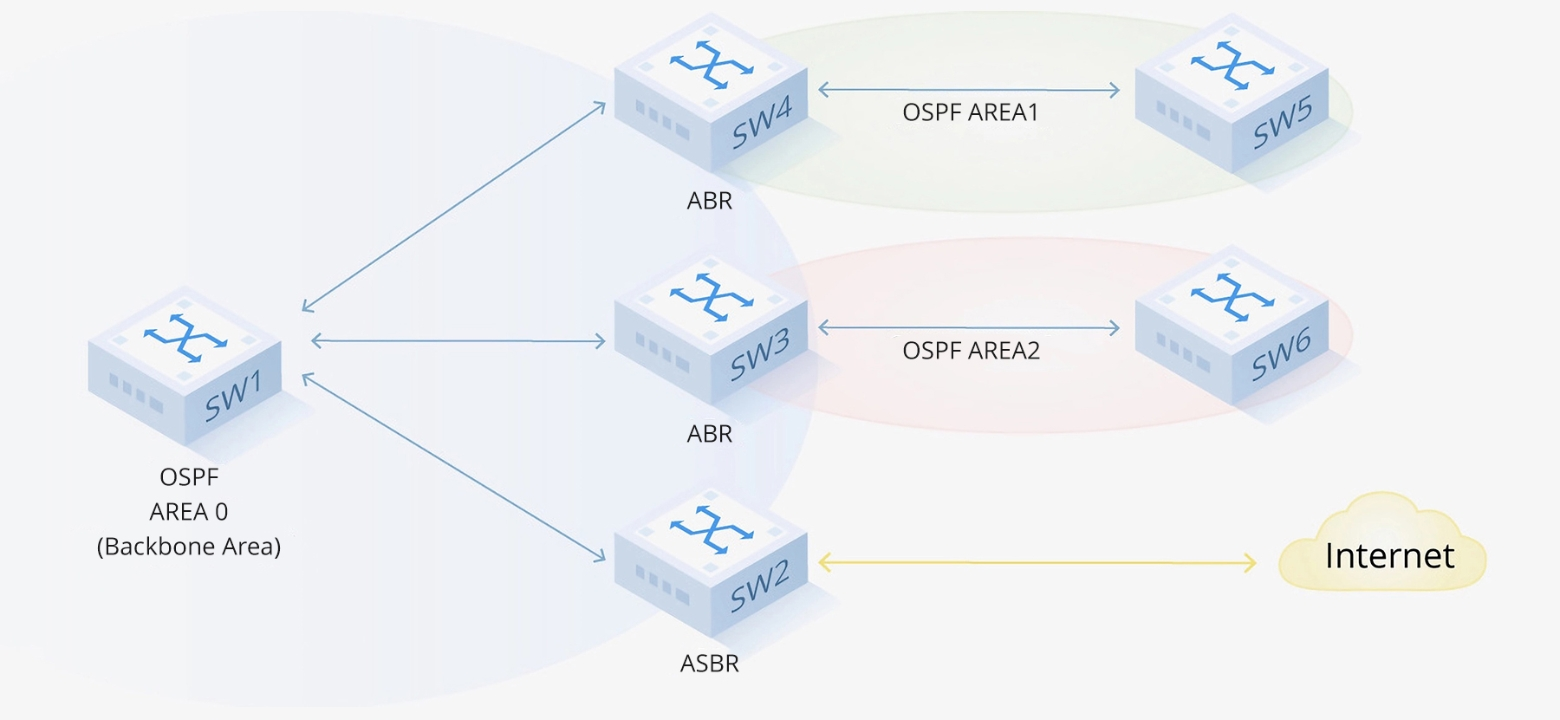
主な特徴
OSPFのパケットタイプ
OSPFは、ネイバー関係を確立し、リンクステート情報を交換するために、以下の5種類のパケットを使用します。
OSPFの動作原理
OSPFのワークフローには、以下の主要なステップが含まれます。
1. ネイバーの検出と確立
ブロードキャストネットワークでは、DR(デザインルーター)とBDR(バックアップDR)を選出し、隣接関係の数を削減する。
2. リンクステートデータベース(LSDB)の同期
隣接ルーター同士でLSA(リンクステート広告)を交換し、LSDBを同期する。
LSAの種類には、ルーターLSA(タイプ1)、ネットワークLSA(タイプ2)、サマリーLSA(タイプ3/4)などがある。
3. 最短経路の計算
4. ルートの更新と維持
更新はリンクステートの変化によってトリガーされ(非定期的)、増分LSAのみを送信する。
Helloパケットは定期的に送信され、ネイバー関係を維持する(デフォルトのデッドインターバルは40秒)。
IGPプロトコル
IGPの特徴
VRRPの動作原理
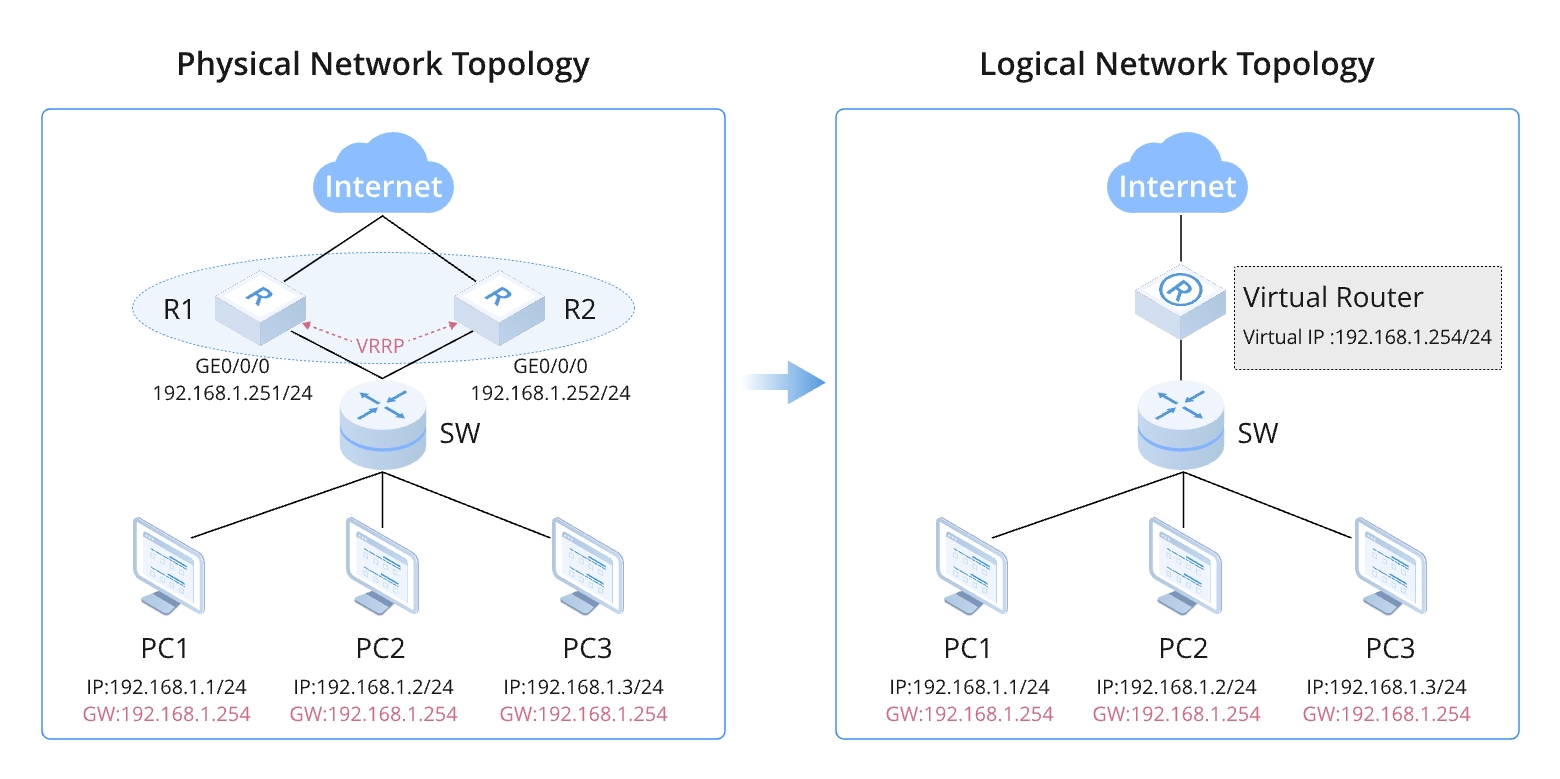
主な特徴
比較:BGP vs. OSPF vs. IGP vs. VRRP
上記の基本概念を理解したうえで、これら4つのプロトコルの違いを明確に区別できます。以下の表に示します。
|
BGP
|
OSPF
|
IGP
|
||
|
プロトコルタイプ
|
冗長プロトコル
|
|||
|
適用範囲
|
クロスAS(WAN、インターネット)
|
単一のAS内(LAN、データセンター)内
|
単一AS内
|
|
|
ルーティングメカニズム
|
パス属性(AS_PATHなど)に基づく
|
リンクステートデータベース(LSDB)に基づく
|
特定のプロトコルによる(OSPF、IS-ISなど)
|
ルーティング選択は不要
|
|
主な機能
|
ルーティング最適化、ポリシー制御、パス選択
|
最短パス計算、高速コンバージェンス
|
ルーティング収束、トポロジー検出
|
ゲートウェイの障害を防止するためのマスター-スレーブ切り替え
|
|
適用シナリオ
|
インターネットバックボーン、データセンター相互接続、企業WAN
|
企業ネットワーク、データセンター、バックボーンネットワーク
|
特定のプロトコルによる(企業向けOSPF、キャリア向けIS-ISなど)
|
企業ネットワーク、WANマスターとバックアップエクスポート
|
まとめ
BGPの解説: BGPの仕組みと重要性
BGPの基本概念
BGPの初期バージョンにはBGP-1(RFC 1105)、BGP-2(RFC 1163)、BGP-3(RFC 1267)があり、現在広く使用されているバージョンはBGP-4(RFC 1771、その後RFC 4271に更新)です。BGP-4は、インターネットにおける外部ルーティングプロトコルのデファクトスタンダードとなっており、ISP(インターネットサービスプロバイダー)によって広く利用されています。
BGP-4は、動的ルーティングメカニズムを通じて、ネットワーク間でのパケット伝送を効率的かつ信頼性の高いものにします。その主な機能は、ネットワークをまたいだルーティングと最適化を実現することであり、これは現代のインターネットやデータセンター間の相互接続の基盤となっています。
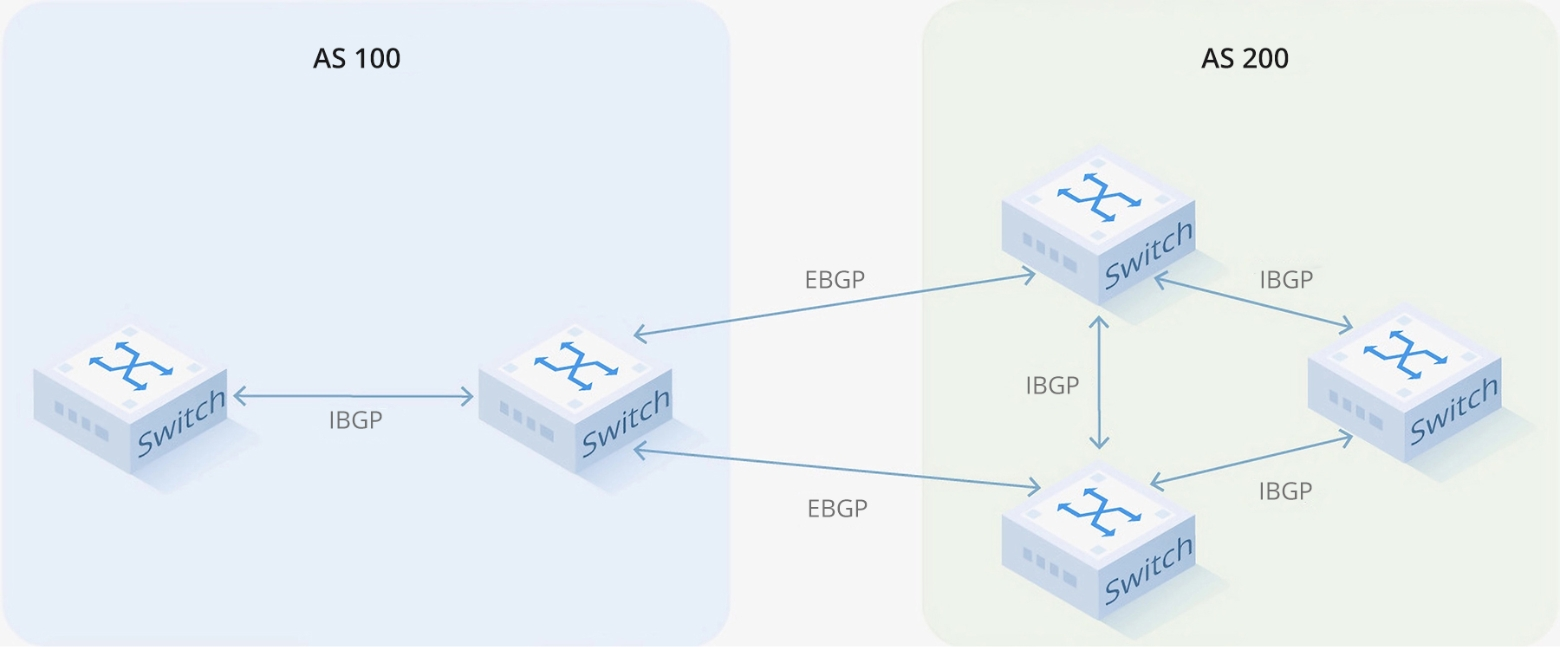
BGPの動作原理
1.自律システム(AS)
自律システム(Autonomous System, AS)とは、単一の組織によって管理され、一貫したルーティングポリシーを持つIPネットワークのグループです。各ASには、インターネット上で識別するための一意のAS番号(ASN)が割り当てられています。BGPは、AS間でルーティング情報を交換することにより、ネットワーク間の通信を可能にします。
2.BGPのネイバー関係の確立
BGPは、ネイバー関係(Peer)を確立することでルーティング情報を交換します。ネイバー確立のプロセスには以下のステップが含まれます。
ネイバータイプ:
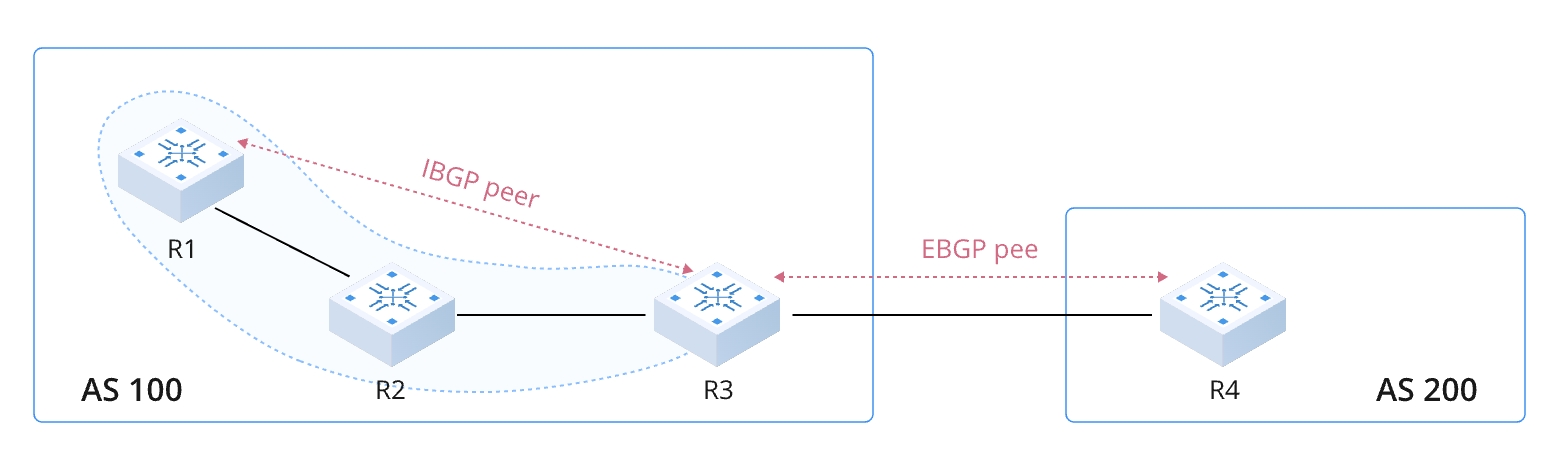
3.ルーティング情報の交換
BGPはUPDATEメッセージを使用してルーティング情報を交換します。各ルートには、ルーティング決定に使用される複数の属性が付加されます。BGPのルーティング属性は以下の4つのカテゴリに分類されます。
一般的なBGPの属性:
4.ルーティングアルゴリズム
BGPは、以下の手順で一連の属性に基づき最適なルートを選択します。
BGPの主な特徴:インターネットを支える理由
BGPはインターネットのコアルーティングプロトコルとして、現代のネットワークアーキテクチャにおいて重要な役割を果たしています。グローバルなインターネット接続の基盤であるだけでなく、企業ネットワーク、データセンター間の相互接続、クラウドコンピューティング環境でも重要な役割を担っています。
ドメイン間ルーティング
BGPは、異なる自律システム(AS)間で最適なルートを選択するために使用されます。パスの長さ、ポリシー、ASの属性など、さまざまな要因を考慮し、最適なルートを選択します。これにより、BGPはインターネットのコアルーティングにおいて重要な役割を果たします。
TCP接続
安定性の要件
ルート伝播ポリシー
BGPは豊富なルーティングポリシーを提供し、柔軟なルートのフィルタリングや選択を可能にします。管理者は、ルートフィルタリング、ルート集約、ルートリダイレクションなど、さまざまなルーティングポリシーを設定することで、異なるネットワーク要件やポリシーに対応できます。
CIDRのサポート
BGPはCIDR(Classless Inter-Domain Routing)をサポートしており、IPアドレスの割り当てをより効率的に行い、ルートの集約を可能にします。これにより、ルーティングテーブルのサイズとルート更新の頻度が削減され、ルーティングの効率とネットワークのパフォーマンスが向上します。
増分ルート更新
BGPはルート更新時に、変更があったルーティング情報のみを送信し、ルーティングテーブル全体を送信することはありません。これにより、ルート伝播に伴う帯域幅とリソースの消費が大幅に削減され、ルート更新の効率が向上します。
ループ防止
BGPはループを回避するように設計されています。AS間では、ASパス情報を使用して通過したASを記録し、ドメイン間ループを防止します。AS内では、学習したルートを同じAS内のBGPネイバーに広告しないことで、AS内ループの発生を防ぎます。
安定性の仕組み
BGPは、ルートの振動や不安定性を防ぐためのいくつかの仕組みを提供しています。ルートパーシスタンス、ルート集約、ルートポリシーなどを活用することで、インターネットネットワークの安定性と信頼性を向上させます。
簡単に拡張可能
BGPは柔軟に設計されており、進化するネットワーク要件に適応できる拡張性を備えています。新しい機能や特性を追加することが可能で、変化し続けるインターネット環境や要求に対応できます。
まとめ
FSが提供できるサポート
FS S5860シリーズスイッチは、柔軟なBGP設定をサポートし、さまざまな規模のネットワークニーズに対応します。高スループット、低遅延、強力なルーティング処理能力により、BGPネットワークの効率的な運用を実現します。BGPをサポートする高性能スイッチソリューションをお探しの方は、ぜひFSまでお問い合わせください。FSは、専門的な技術サポートとサービスを提供し、ネットワークパフォーマンスの包括的な向上を支援します。